
Les fondamentaux
C'est quoi le SEO technique ?
Le SEO technique désigne les actions mises en place au niveau du site et du serveur pour faciliter la découverte, la compréhension, et l’indexation de votre site par les moteurs de recherche, dans le but d’améliorer à la fois votre visibilité dans les moteurs et l’expérience utilisateur.
Le SEO technique, ou technical SEO en anglais, couvre un ensemble de domaines qui ont tous un impact sur le référencement naturel (gratuit) d’un site web :
Exploration et indexation de votre site par les moteurs de recherche
Accès et découverte du contenu à travers la structure du site
Vitesse du site
Données structurées
Pour chacun de ces domaines, nous développerons sur cette page les optimisations techniques et bonnes pratiques nécéssaires pour optimiser votre référencement technique.
Pourquoi c'est important ?
Le SEO technique est la fondation de votre succès sur les moteurs et peut avoir un impact radical sur le nombre de visiteurs que vous recevez en provenance des moteurs de recherche, dans un sens ou dans l’autre.
Oui, les optimisations techniques du référencement peuvent augmenter votre trafic depuis Google, mais de manière peut-être plus importante encore :

Certaines erreurs au niveau du SEO technique, parfois faciles à faire, peuvent aboutir sur le blocage total du trafic en provenance de Google et des autres moteurs de recherche.
Zéro visiteurs, même avec le meilleur contenu du monde.
Pas de panique ceci-dit, l’essentiel du SEO technique reste accessible sans compétences techniques poussées, et offre les avantages suivants :
Améliorer votre référencement sur Google
En mettant en place les bonnes pratiques techniques vous ferez en sorte :
Que Google et les autres moteurs découvrent, explorent, et comprennent vos contenus.
De résoudre les erreurs qui envoit des signaux négatifs à Google, et limitent votre référencement.
D’attirer l’attention de Google sur vos pages les plus importantes, et ne pas gâcher le temps que Google passe sur votre site avec des pages sans enjeux.
A l’inverse, si votre site a des erreurs techniques importantes, Google :
Ne trouvera pas certaines de vos pages.
Ne pourra pas “lire” et comprendre le contenu de vos pages.
Evaluera votre site de manière négative, et référencera mal votre site.
Pourra dans le pire des cas ne pas du tout indéxer votre site.
Améliorer l'expérience utilisateur
Votre site ne doit pas être construit que pour les moteurs de recherche.
Pour les utilisateurs, les avantages sont les suivants :
Une expérience de navigation performante, qui permet aux visiteurs de parcourir vos contenus rapidement et facilement.
Une absence d’erreurs qui empêchent une bonne une expérience : pages 404, erreurs de chargement, etc.
Un site qui charge rapidement.
Un site qui fonctionne bien sur téléphone.
Gardez le bien à l’esprit :
“Le SEO technique est une nécessité, pas une option.”
Partie 1 : Optimiser le crawling et l'indexation de votre site
Cette première partie aborde les bonnes pratiques pour optimiser le processus de découverte et d’indexation de votre site par les moteurs de recherche.
Comprendre les principes du crawling et de l'indexation
Le processus d’ajout d’une page aux résultats de Google et des autres moteurs de recherche passe par les étapes suivantes :
L'exploration (Crawling)
Les robots d’exploration des moteurs de recherche parcourent le web à travers les liens hypertextes à la recherche de nouvelles pages à évaluer et présenter, ou non, à leurs utilisateurs.

Quelques éléments qui impactent l’exploration de vos pages web par les robots d’exploration :
L’ancienneté de votre site
L’accessibilité de la page
La structure d’url
Les robots d’exploration des différents moteurs ont un nom qui leur est propre, qui permet des les identifier quand ils visitent votre site :
- Googlebot
- Bingbot
- Slurpbot (Yahoo)
- Duckduckbot
- Baiduspider
- Yandexbot
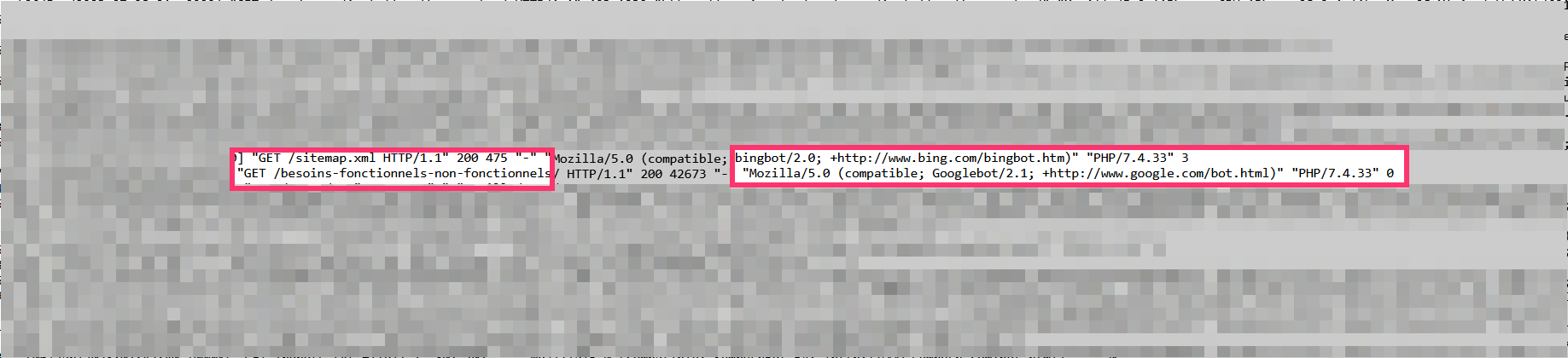
Dans les logs ci-dessous, je vois par exemple que Bingbot a visité le fichier sitemap.xml de savoir.plus et que Googlebot une page spécifique du site :
L'affichage de la page (Rendering)
Les robots d’exploration éxécutent ensuite le code html de la page pour “voir” la page.
Chez Google, ce processus est assuré par un outil interne appelé Rendertron.

Les moteurs voient le contenu de votre site sans le style, mais voient les liens qui leur permettront d’explorer d’autres pages :

Ils affichent la structure de titres :

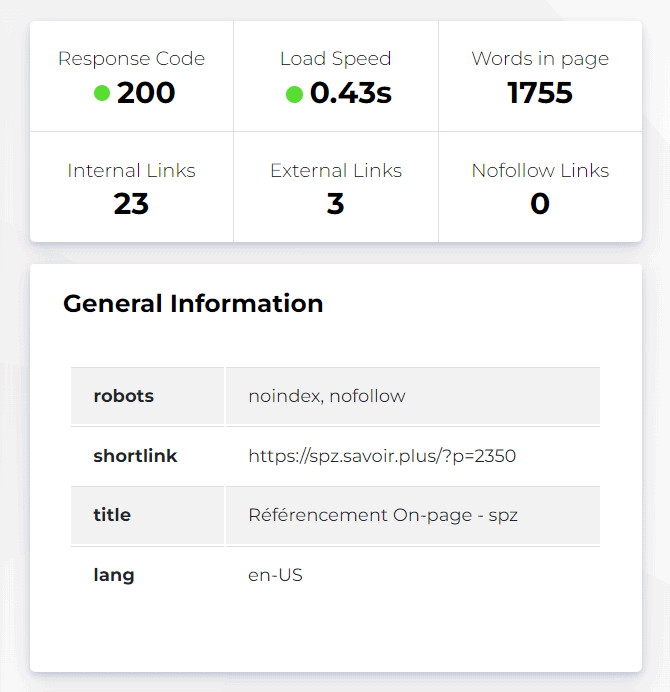
Ils mesurent un certain nombre d’éléments par rapport à la page, comme sa vitesse de chargement, et renvoient le statut de la page :
L'indexation (Indexing)
Après exploration et affichage de la page, les moteurs vont identifier le contenu et le sens de la page, et décider s’ils ajoutent ou non la page à leur index.
A noter :
C’est quoi l’index d’un moteur de recherche ?
Pour être indéxée, une page doit d’abord être “crawlée”
Les moteurs indexent des pages, pas des sites
- Le processus d’exploration et d’indexation fonctionne page par page.
- Dans de nombreux cas, les moteurs n’indexent pas toutes les pages d’un site.
La qualité est un facteur d’indexation
Une page non indéxée n’apparaîtra pas dans les SERP
Indéxé ne veut pas forcément dire bien positionné
Le classement (Ranking)
Une fois que la page est indéxée, le moteur de recherche va la positionner par rapport aux autres sites de son index, en fonction de l’évaluation de la qualité de la page et du site.
Les facteurs de référencement liés à la qualité et la popularité sont abordés dans des parties dédiées de notre cours sur le SEO :
Choisir les pages que vous ne voulez pas indexer
On pourrait être tenté de vouloir que les moteurs indexent toutes les pages de notre site, pour un maximum de visibilité et de trafic, mais il existe des pages qu’il est important de ne pas indexer.
Les pages réservées à des cibles spécifiques
- Pages “mon compte”.
- Pages qui permettent d’accéder à des ressources payantes.
- Landing pages avec une offre réservée à certains publics.
- Pages admin, comme /wp-admin/ sur Wordpress
- Etc.
Pages qui apportent peu ou pas de valeur ajoutée
- Pages avec peu de contenu.
- Contenu dupliqué. (Plus d’informations à ce sujet plus bas sur cette page)
- Pas existantes mais pas terminées.
Notez que si vous ne limitez pas l’exploration et l’indexation des pages qui apportent peu ou pas de valeur ajoutée aux internautes, cela peut envoyer des signaux négatifs aux moteurs de recherche, et avoir un impact négatif sur le référencement des pages qui sont elles importantes.
Choisir les pages à ne pas indexer pour optimiser votre budget d'exploration
C’est quoi le budget d’exploration ?
Crawl budget en anglais, c’est le nombre d’urls que Google va crawler pendant une période donnée.
Si vous ne donnez aucune restriction à Google quant à l’exploration de vos pages, il se peut que vous vous dépensiez tout votre budget d’exploration, avec comme conséquence que certaines pages de votre site ne seront pas explorées.
L’objectif est alors de bloquer l’exploration de certaines pages, pour que le budget d’exploration soit dépensé sur les pages que vous souhaitez réellement référencer.
Cependant, le budget d’exploration n’est un problème que dans quelques cas spécifiques :
- Si votre site a des milliers de pages que vous souhaitez crawler, par exemple pour un gros site e-commerce.
- Si vous venez d’ajouter de nombreuses pages d’un coup (des centaines).
Créer un sitemap
Le sitemap est un fichier qui présente aux moteurs de recherche les différentes pages de votre site, dans un format standardisé :

En savoir plus sur le sitemap
Le sitemap est pour les moteurs de recherche
Il y a une différence entre un sitemap destiné aux moteurs de recherche, visible sur l’exemple ci-dessus, et les plans de site visibles sur de nombreux sites web, destinés aux internautes :
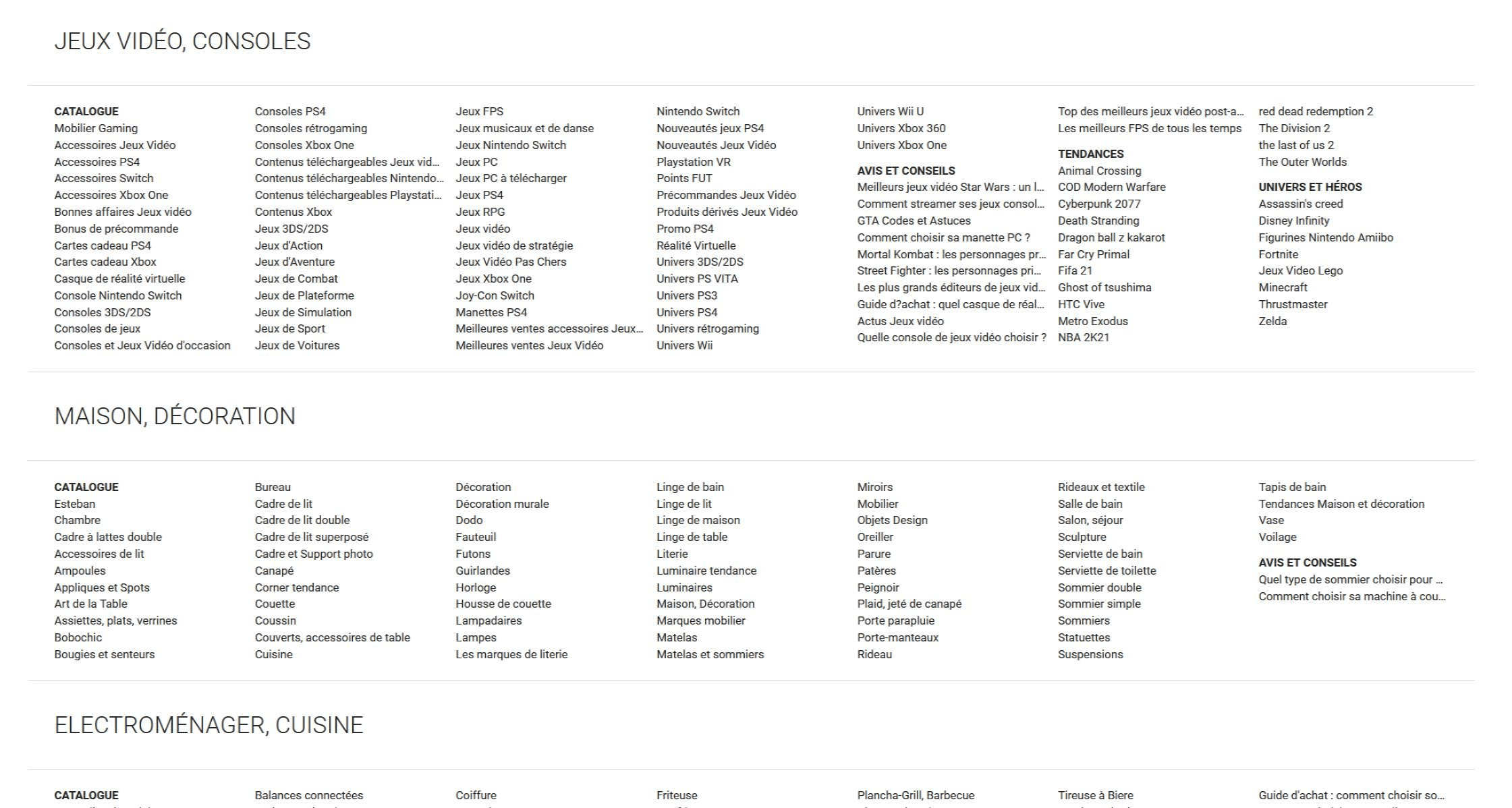
Le plan du site de la Fnac. Ceci n’est pas un sitemap.
Les différents types de sitemaps

Le sitemap xml standard : le plus commun
Il liste les différentes pages de votre site.
Le sitemap du Monde
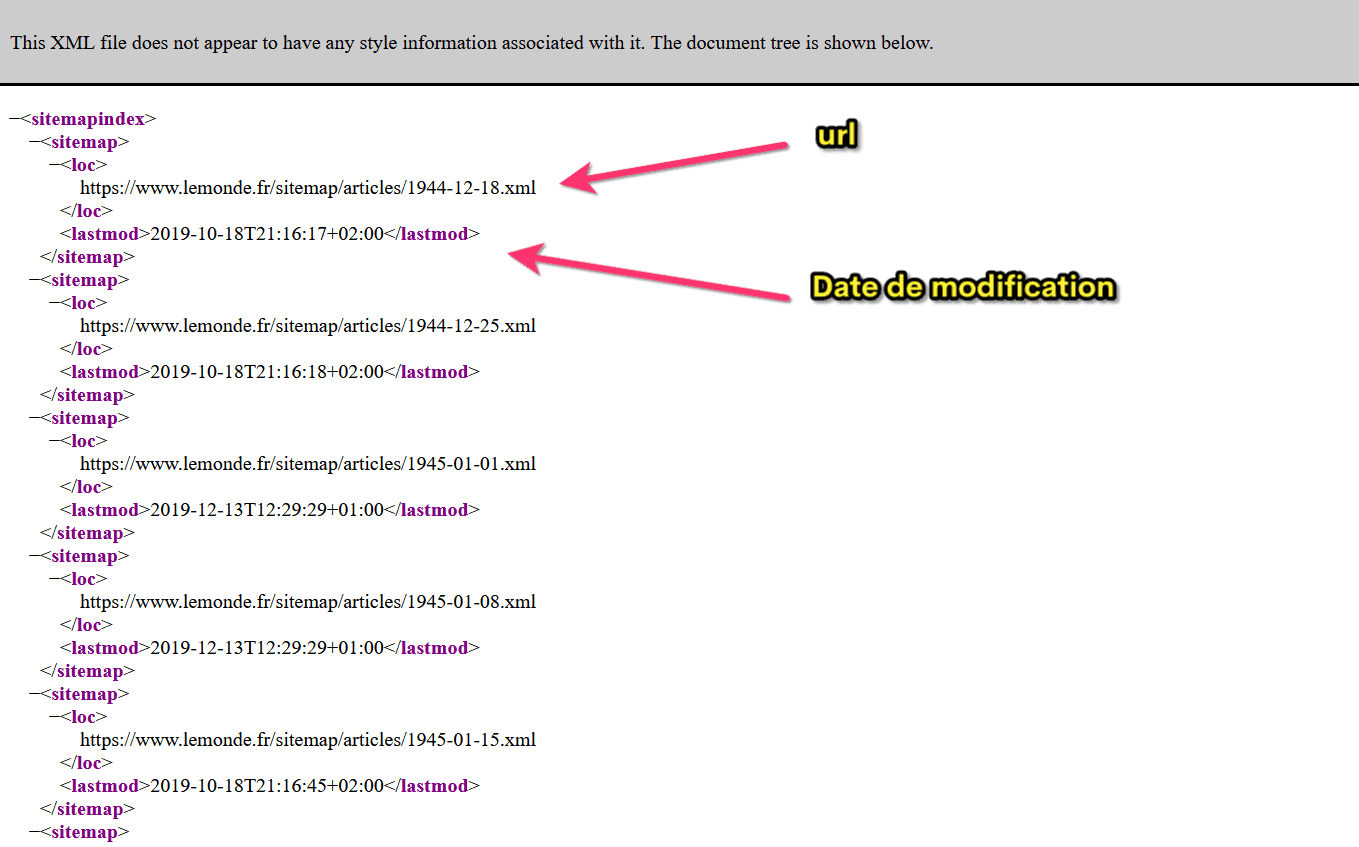
Le sitemap peut aussi indiquer aux moteurs les pages à explorer en priorité, ainsi que la fréquence de mise à jour des contenus :


Les sitemaps de vidéos
Ils listent les vidéos présentes sur un site, et présentent des données supplémentaires relatives à chaque vidéo :
- Lien de l’image d’aperçu.
- Description.
- Personne ou organisation qui a uploadé la vidéo.
- Etc.
Un sitemap vidéo selon Google


Les sitemaps d’image
Ils sont utilisés pour indiquer à Google la liste des images présentes sur les différentes pages de votre site, et les métadonnées des différentes images :
- Créateur de la photo
- Légende
- Description
- Localisation
- Etc. (liste complète)
Un exemple de sitemap image selon Google


Les sitemaps Google Actualités
Ils sont réservés aux sites approuvés sur Google Actualités.
Pourquoi créer un sitemap ?
Selon les propres mots de Google, le sitemap n’est pas une obligation pour que vos pages soient bien crawlées et indexées :
“Si les pages de votre site sont correctement liées entre elles, Google est généralement en mesure de découvrir la majeure partie de votre site.”
Notons quand-même que ceci s’applique si les pages sont correctement liées entre elles, ce qui n’est souvent pas le cas.
Toujours selon Google, le sitemap n’est pas indispensable dans les cas suivants :
- Si votre site est de taille modeste.
- Si chacune de vos pages est accessible avec au moins un lien.
- Si vous ne souhaitez pas indexer tous vos fichiers multimédias.
A l’inverse, la création d’un sitemap est fortement recommandée dans les cas suivants :
- Si votre site est récent et a peu de liens entrants (backlinks) qui pointent vers lui.
- Si votre site est très volumineux.
- Si votre site comprend de nombreuses pages et que le maillage de liens internes n’est pas exhaustif.
Dans tous les cas, la mise en place d’un sitemap est très facile.
Important
Compte-tenu de ses bénéfices, il est généralement recommandé d’en créer un dans tous les cas.
Bonnes pratiques
Créez un sitemap et mettez le à jour régulièrement
Facile à mettre en place et gratuit, le sitemap vous permet de faire connaître vos pages importantes à Google, ainsi que les nouvelles que vous ajoutez au fil du temps.
Sur WordPress
De nombreux plugins vous audent à automatiser la création de sitemaps, et leur mise à jour quand vous ajoutez du contenu :
- Rank Math
- Yoast
- All In One SEO
- Etc.
Sur les sites réalisés sans CMS, ou avec un CMS qui ne propose la génération automatique de sitemaps :
Vous pouvez utiliser des outils comme https://www.xml-sitemaps.com/, qui scannent votre site, et créent le fichier sitemap que vous pourrez uploader sur votre serveur.
A noter que la démarche devra être répétée à chaque fois que vous ajoutez du contenu sur le site.
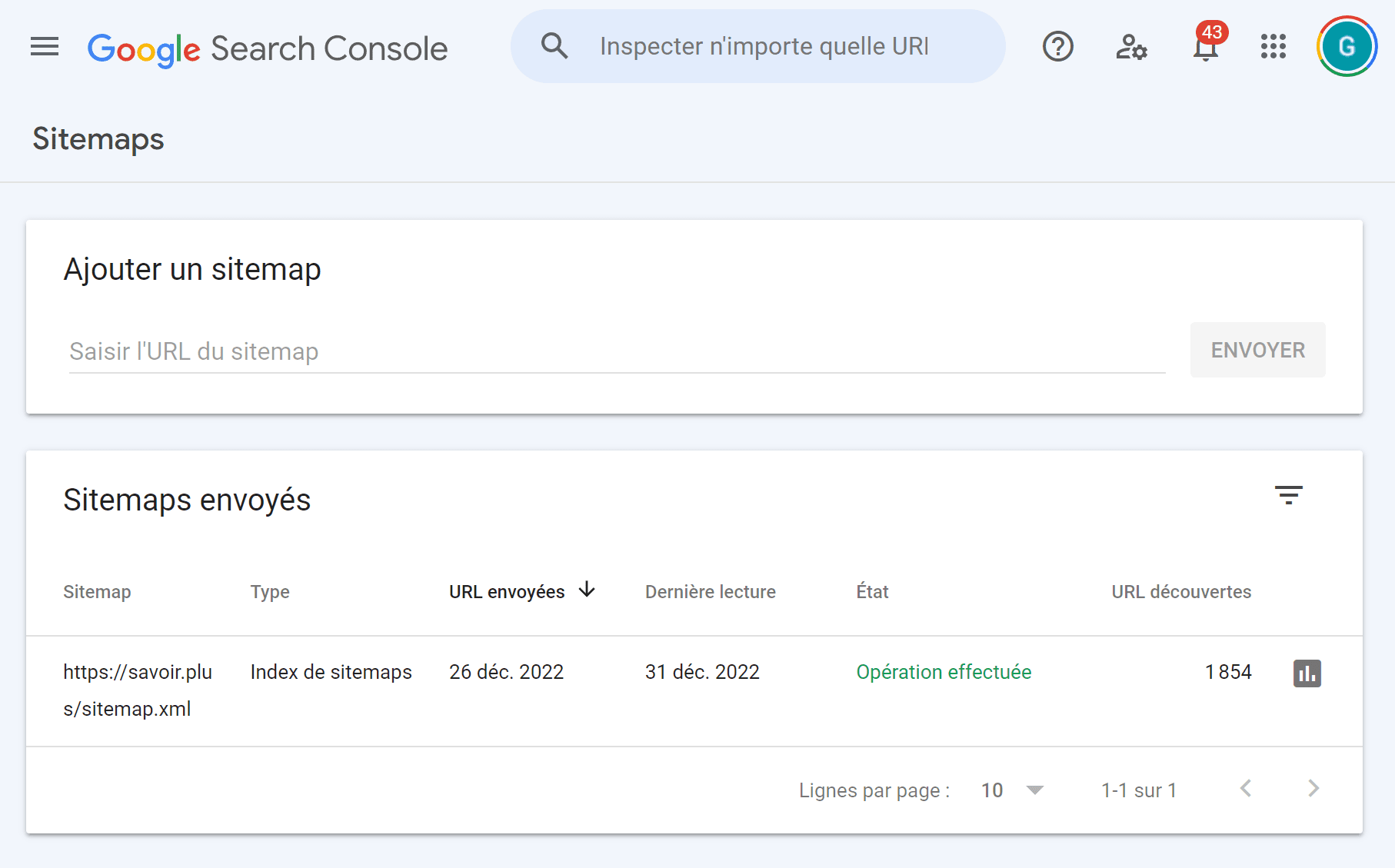
Soumettez votre sitemap sur Google Search Console
Google propose un outil gratuit pour surveiller et régler un certain nombre de points liés à votre présence sur Google, et vous auriez tord de vous en priver :
L’interface où on peut soumettre son sitemap sur Google Search Console
Search Console offre plusieurs informations pour les propriétaires de sites, parmi lesquelles un certain nombre de données relatives à la façon dont Google parcoure votre site :
La liste des sitemaps connus par Google

Pourquoi avoir plusieurs sitemaps ?
Avoir un sitemap est utilse dans au moins les cas suivants :
- Vous avez un sitemap général, un sitemap images, un sitemap vidéos.
- Vous créez un sitemap par type de contenu (articles, guides, images, etc.)
- Votre site a de très nombreuses pages, et dépasse la limite de 50 MO ou 50000 urls.
Le nombre d’url crawlées
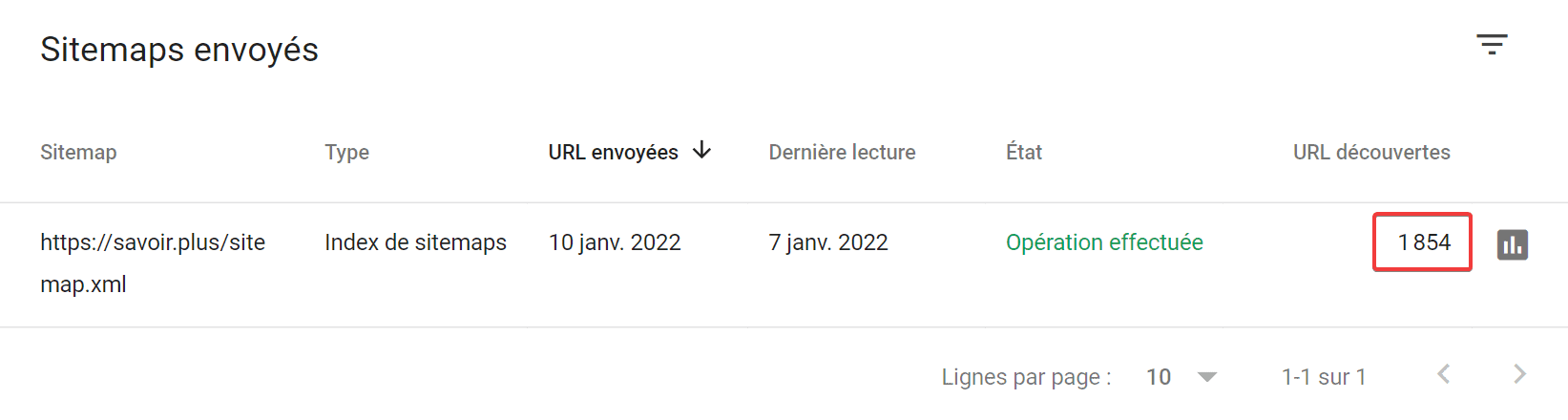
Des informations sur l’indexation de votre site

Vous pouvez ensuite les pages non indexées, et voir :
- S’il s’agit de pages que vous avez demandé à Google de ne pas indéxer.
- Ou s’il s’agit de pages que vous souhaitez indéxer, mais que Google a choisi de ne pas indéxer.


Créez plusieurs sitemaps si nécessaire
Il existe des cas où ou vous pouvez, ou devez avoir plusieurs sitemaps.
Les cas où la création de plusieurs sitemaps est obligatoire
Quand le site a plus de 50 000 urls.
Quand le fichier pèse plus de 50 MO.
Les cas où la création de plusieurs sitemaps est possible mais pas obligatoire
Si vous souhaitez avoir un sitemap pour les pages, un autre pour les images, ou un autre pour les vidéos.
Si vous souhaitez segmenter les données dans Search Console, et avoir des informations pour chaque sitemap. Dans l’exemple ci-dessous, vous pouvez voir la date du dernier passage de Google, qui varie pour chaque sitemap :

Placez votre sitemap à la racine de votre serveur
Le meilleur endroit pour placer vos sitemaps est à la racine de votre serveur.
Le meilleur endroit pour placer votre sitemap selon Google


N'incluez que les pages que vous voulez voir apparaître sur Google
Comme nous l’avons vu plus haut, certaines pages ne doivent pas être visibles sur Google.
- Les pages résevées aux membres.
- Les pages avec peu de contenu.

N'incluez que des urls canoniques
Une url canonique est l’url la plus représentative d’une même page qui peut être accessible à travers plusieurs urls.
Vous trouverez plus de détails sur la notion d’url canonique, et des exemples, plus bas sur cette page.

N'incluez que des urls correctes et absolues
Assurez-vous que les urls présentes dans votre sitemap existent bien (pas d’erreurs 404), et qu’elles ne contiennent pas de fautes de frappes.
Par ailleurs, Google recommande de rédiger les urls au format absolu :


Utilisez l'attribut <lastmod> et ne perdez pas de temps avec les attributs <priority> and <changefreq>
Cette bonne pratique s’appuie encore une fois sur les recommandations de Google :

Créer un fichier robots.txt et utiliser la balise meta-robots
Le fichier robots.txt
Il s’agit d’un fichier texte qui donne des directives aux robots des moteurs de recherche quant aux pages, répertoires ou fichiers qu’ils peuvent ou ne peuvent pas explorer.

Le fichier robots.txt d’Airbnb
Le fichier doit être placé sur le serveur qui héberge le site, à la racine.
Si votre site est monsite.com, le fichier doit être accessible à monsite.com/robots.txt.
En référencement, les agents utilisateurs (user-agents) désignent les robots d’exploration des moteurs de recherche : Googlebot, Bingbot, DuckDuckbot etc.
Disallow signifie “interdire” en anglais, et sert donc à désigner les pages, répertoires ou fichiers qu’on souhaite que les moteurs n’explorent pas.
On peut aussi interdire l’exploration de toutes les pages qui appartiennent à la section réservée aux membres, en ciblant le répertoire entier :
Dans cet exemple, toutes les urls de la section membres seront interdites à l’exploration :
- monsite.com/membres/mon-compte
- monsite.com/membres/factures
- monsite.com/membres/sav
- Etc.
“*” est une expression régulière, wildcard en anglais. Dans le fichier robots.txt, “*” est utilisé pour cibler tous les robots d’exploration.
Allow signifie “autoriser” en anglais, et désigne les pages, répertoires ou fichiers qu’on souhaite que les moteurs explorent.
Notez que cet exemple spécifique n’est pas nécessaire, car sans fichier robots.txt, tous les moteurs sont autorisés à explorer le site par défaut.
Le caractère *$* à la fin de chaque directive Disallow est une expression régulière qui spécifie que “.pdf”, par exemple, doit correspondre à la fin de l’URL.
Cela garantit que seules les URL se terminant par les extensions de fichiers spécifiées seront exclues, et non les URL qui contiennent les extensions de fichiers dans le chemin d’accès à l’URL.
Le fait de ne pas écrire “Allow” revient à autoriser toutes les urls hormis celles qui sont explicitement interdites : les fichiers pdf et Powerpoint dans notre exemple.
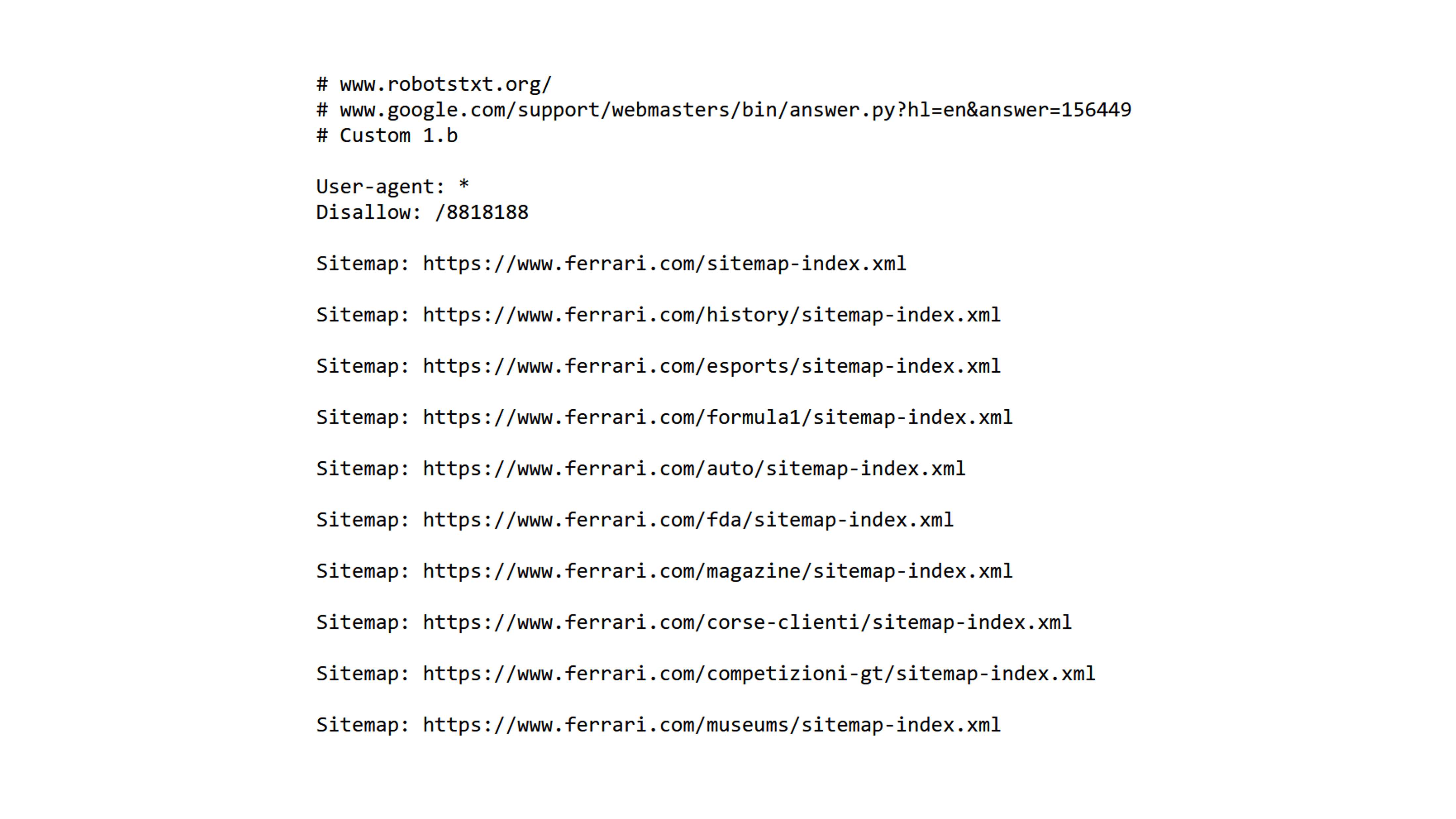
Ferrari qui liste ses différents sitemaps sur son fichier robots.txt.
La balise meta robots
Cette balise intégrée dans la section < head > d’une page web est utilisée pour donner des instructions aux robots des moteurs de recherche quant à son indexation.
Bonnes pratiques et éléments à retenir
Identifiez les urls sensibles et marquez les en Disallow dans votre sitemap
Quelques exemples réels en plus de ceux qui ont été donnés ci-dessus :
Nike qui bloque le crawling des messages privés échangés sur son site
Nike qui demande à un moteur de recherche chinois de ne crawler que la partie du site dédiée à la Chine
Etudes-et-analyses.com qui bloque l’accès à des ressources téléchargeables payantes
Utilisez Noindex plutot que Disallow pour vous assurer qu'une page n'apparaisse pas dans les moteurs
Il existe au moins un cas où l’utilisation de Disallow ne suffit pas :
Vous écrivez une directive dans votre fichier sitemap pour interdire l’exploration d’une page XYZ.
Cette directive fera que les moteurs n’exploreront pas cette page, et par conséquent ne l’indexeront pas.
Si maintenant un site tiers envoit un lien vers la page XYZ, les moteurs l’exploreront et pourront finir par l’indexer.
Dans ce cas, les robots d’exploration ne découvriront pas la page depuis votre sitemap, mais depuis le lien en provenance d’un site tiers.
Pour éviter cela, utilisez une balise meta robots en noindex sur la page XYZ.
Attention aux risques !!!
L’utilisation du sitemap et de la balise meta-robots doit être menée avec soin, pour éviter les déconvenues parfois sévères.
Impacter négativement votre référencement
Si vous vous trompez, vous pourrez donner des directives contreproductives, qui auront un effet négatif sur votre référencement :
- Pages importantes marquées non crawlables ou non indexables.
- Blocage des liens internes, qui pourront impacter négativement votre maillage de liens internes.
Les risques de sécurité
N’importe qui peut consulter votre fichier robots.txt, et celui-ci peut indiquer des ressources importantes que vous souhaitez protéger.
N’importe qui peut alors essayer d’accéder à ces ressources.
Il ne suffit donc pas de demander aux moteurs de recherche de ne pas y accéder : protégez-les aussi par mot de passe.
Utilisez des outils pour vous aider à rédiger les directives
Les utilisateurs les plus aguerris rédigeront leurs directives à la main, mais des outils peuvent vous aider et réduire les risques liés à une mauvaise utilisation du fichier sitemap ou des balises meta robot.
Si votre site est fait sur WordPress
- Yoast SEO
- All in One SEO
- RankMath
Ces plugins, en plus d’autres fonctionnalités, génèreront les fichiers et balises en fonction des choix que vous faîtes sur une interface graphique.
Si votre site n’est pas fait avec Worpress
Ces outils vous permettent de générer un fichier robots.txt, en fonction des choix que vous faîtes sur une interface graphique. Il vous faudra ensuite uploader ce fichier à la racine de votre site.
Eviter le contenu dupliqué avec les url canoniques
Les urls canoniques, avec la balise canonical, permettent d’éviter les pénalisations que les moteurs peuvent infliger à votre site pour des raisons de contenu dupliqué.
La notion de contenu dupliqué
C'est quoi ?
Un site web présente parfois (souvent) des contenus dupliqués, c’est à dire plusieurs pages ayant des urls différentes, mais qui présentent entièrement ou presque le même contenu.
Ce contenu dupliqué peut pénaliser le référencement :
- Des pages dupliquées concernées.
- De tout votre site, s’il comporte de nombreuses pages dupliquées.
Le contenu dupliqué est très fréquent
Même si vous créez du contenu original sur chaque page, et ne copiez-collez pas votre contenu d’une page à l’autre, le contenu dupliqué peut arriver très facilement.
Exemples de contenus dupliqués légitimes
Certains CMS pourront créer plusieurs urls pour un même produit
Google considère les pages avec et sans WWW comme des pages différentes
Google considère les pages avec et sans https comme des pages différentes
Exemples de contenus dupliqués frauduleux
Dans les cas ci-dessous, l’intention résulte d’actions désapprouvées clairement par Google, car elles vont à l’encontre de sa volonté de présenter des résultats de qualité à ses utilisateurs
Copier-coller du contenu trouvé sur le web sur votre site
Copier tel quel du contenu existant sur le web sans autorisation est un moyen d’obtenir du contenu rapidement, mais en plus d’être illégal, cela vous pénalisera très certainement auprès de Google, qui préfèrera mettre en avant la source originale du contenu.
Copier-coller du contenu en masse
- Certains sites ont des robots qui parcourent le web pour copier-coller du contenu en masse.
- Comme vu ci-dessus, cette pratique dévalue fortement les sites qui l’utilisent auprès de Google.
Les risques du contenu dupliqué
Etre pénalisé par Google
- Si Google propose des contenus dupliqués dans ses résultats, il n’apporte pas de valeur ajoutée à ses utilisateurs.
- C’est pourquoi Google favorise les contenus originaux.
Notez que Google peut désindexer complètement un site qui propose du contenu dupliqué, mais cela ne concerne que les sites qui proposent du contenu dupliqué en masse de manière frauduleuse.
Cannibaliser votre référencement
Avoir des pages dupliquées revient à mettre en concurrence ses propres pages dans Google.
Laisser le choix à Google
Sans indication spécifique de votre part, Google fera un choix, mais ce ne sera pas forcément celui que vous aurez souhaité :
“Si l’une des pages de votre site est accessible via plusieurs URL, ou si différentes pages de votre site présentent un contenu similaire (par exemple, une page avec une version mobile et une version classique), Google les considère comme des versions en double de la même page. Google choisira une URL comme version canonique et c’est celle-ci qui sera explorée. Toutes les autres URL seront considérées comme des URL en double et explorées moins souvent.” Source : Google
La solution : les urls canoniques
C'est quoi ?
Du point de vue de Google
“L’url la plus représentative d’une page, parmi un groupe de pages dupliquées.”
Du point de vue des référenceurs
“La page que l’on demande aux moteurs de recherche de considérer comme originale.”
Bonnes pratiques
Choisir la meilleure version parmi un groupe d'urls dupliquées
La première étape consiste à définir la meilleure url, celle que vous voulez que Google considère comme canonique.
Votre choix pourra s’opérer en fonction des éléments suivants :
Http vs Https
C’est la version https qui doit être canonique.
La qualité de la page
Choisissez comme canonique l’url qui présente la meilleure qualité, déterminée par exemple sur la qualité visuelle ou l’exhaustivité de la page.
WWW vs pas de WWW
L’un ou de l’autre ne présente pas en soi d’avantage spécifique sur votre référencement, mais il convient de faire un choix.
Définir les urls canoniques avec la balise rel=canonical
Cette balise doit être placée dans le section <head> :
Des pages non canoniques
Chaque url non canonique aura donc ce morceau de code dans la section <head>
De la page canonique
Ceci n’est pas obligatoire si la balise rel=”canonical” est bien renseignée sur toutes les versions canoniques, mais ce n’est pas une mauvaise idée de rappeler aux moteurs qu’ils sont sur l’url.
Est-ce qu'il faut supprimer les urls non canoniques ?
Dans plupart des cas, il est préférable de ne pas supprimer les urls dupliquées.
Les urls dupliquées peuvent bénéficier à votre référencement off-page
Comme vous ne maîtrisez pas la façon dont vos visiteurs partagent vos contenus, il arrive parfois que les internautes partagent, ou envoient des backlinks à la version non canonique d’une url.
Si vous supprimez les urls non canoniques, vous risquez de perdre des signaux de popularité précieux :
- Partages de vos contenus sur les réseaux sociaux.
- Backlinks
Notez qu’aux yeux de Google, ces signaux de popularité seront répercutés à l’url canonique, améliorant ainsi leur référencement, si vous avez bien indiqué l’url canonique.
Pour ces mêmes raisons, il peut être une bonne idée d’autoriser l’exploration de ces urls
L’idée est de ne pas marquer les urls en Disallow sur votre sitemap, de manière à ce que Google puisse les explorer et prendre connaissance de ces signaux de popularité.
Utiliser des outils
Comme d’habitude, il existe un certain nombre d’outils qui vous aident dans votre démarche.
Pour trouver des contenus dupliqués
Pour renseigner les balises canonical
Les plugins SEO sur WordPress embarquent des fonctionnalités qui vous permettent de renseigner les balises canonical sans entrer dans le code.
WWW vs pas de WWW
L’un ou de l’autre ne présente pas en soi d’avantage spécifique sur votre référencement, mais il convient de faire un choix.
